Interrupt란?
CPU에서 프로그램을 실행하고 있을 때, I/O 디바이스 등에서 예외상황(키보드 입력, 마우스 클릭 등)이 발생했을 때 처리가 필요한 경우에 CPU에게 알려서 처리되게 하는 것을 말한다...라고 위키피디아에 쓰여있다.
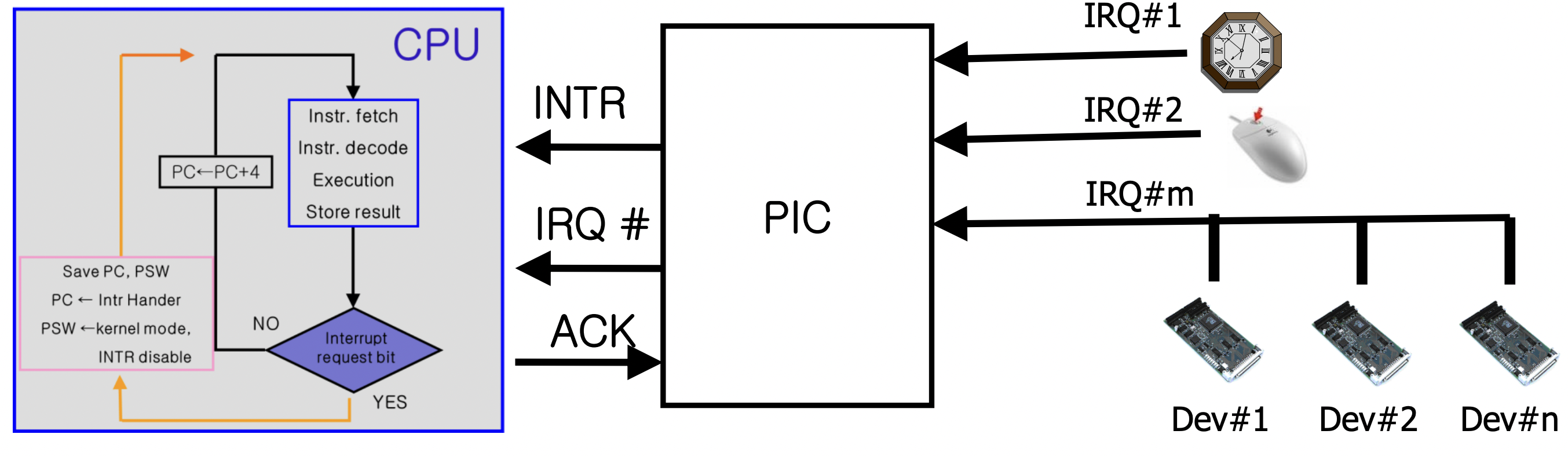
CPU는 Fetch - Decode - Execution을 반복한다고 이전 글에서 설명했다. 이제 저기에 Interrupt가 왔는지 안왔는지 체크하는 과정이 추가가 된다. 키보드, 마우스, 시스템 타이머 등 I/O 디바이스들은 CPU에 직접 연결하는 것이 아니라 Programmable Interrupt Controler(PIC)에 연결 되어있다. PIC이 CPU와 연결되어 있는데, PIC에서 CPU에게 Interrupt가 있는지 없는지 알려준다. Interrupt가 없다면, 그냥 하던대로 명령어를 실행하고 Interrupt과 왔다면 IRQ #을 확인한다. IRQ는 Interrupt Request Number을 의미하는데 어떤 I/O 디바이스에서 Interrupt가 왔는지를 의미한다고 생각하면 된다. 그리고 이제 Interrupt에 관한 명령어들을 처리하게 된다.
참고로, PIC의 역할은 간단하게 2가지가 있다고 생각할 수 있다.
1. I/O device의 request를 vector(번호)로 변환해준다. 그리고 CPU에게 vector(IRQ #)과 함께 Interrupt 신호를 준다. 그리고 ACK을 기다린다. ACK은 CPU가 PIC에게 Interrupt를 확인했다고 알려주는 신호이다.
2. Interrupt들을 "mask"(disable) 처리 할 수 있다. programmable이라는 이름이 붙은 이유인데, 특정 Interrupt를 잠시 보류(pending)시킬 수가 있다. 아니면 Interrupt에 우선순위를 둘 수도 있다.
Interrupt Mechanism

I/O 디바이스들은 CPU보다 훨씬 느리다. 초창기의 컴퓨터에서는 CPU가 I/O 디바이스의 처리가 끝날 때까지 기다려야만 했는데, CPU를 활용도가 너무 낮았다. 그래서 I/O 디바이스가 처리될 때 CPU는 다른 일을 하고 있다가 I/O 디바이스가 CPU한테 나 일 끝났다고 알려주는 방식이 생기게 되었다. 이것이 바로 Interrupt이다. 위의 그림에서 그걸 보여준다. 명령어 실행 잘하고 있다가 Interrupt가 발생하니까 PC에 Interrupt Handler의 주소가 담기게 되어서 잠깐 다른 명령어를 처리한다. 그리고 다시 아까 하던 명령어를 실행하고 있다.
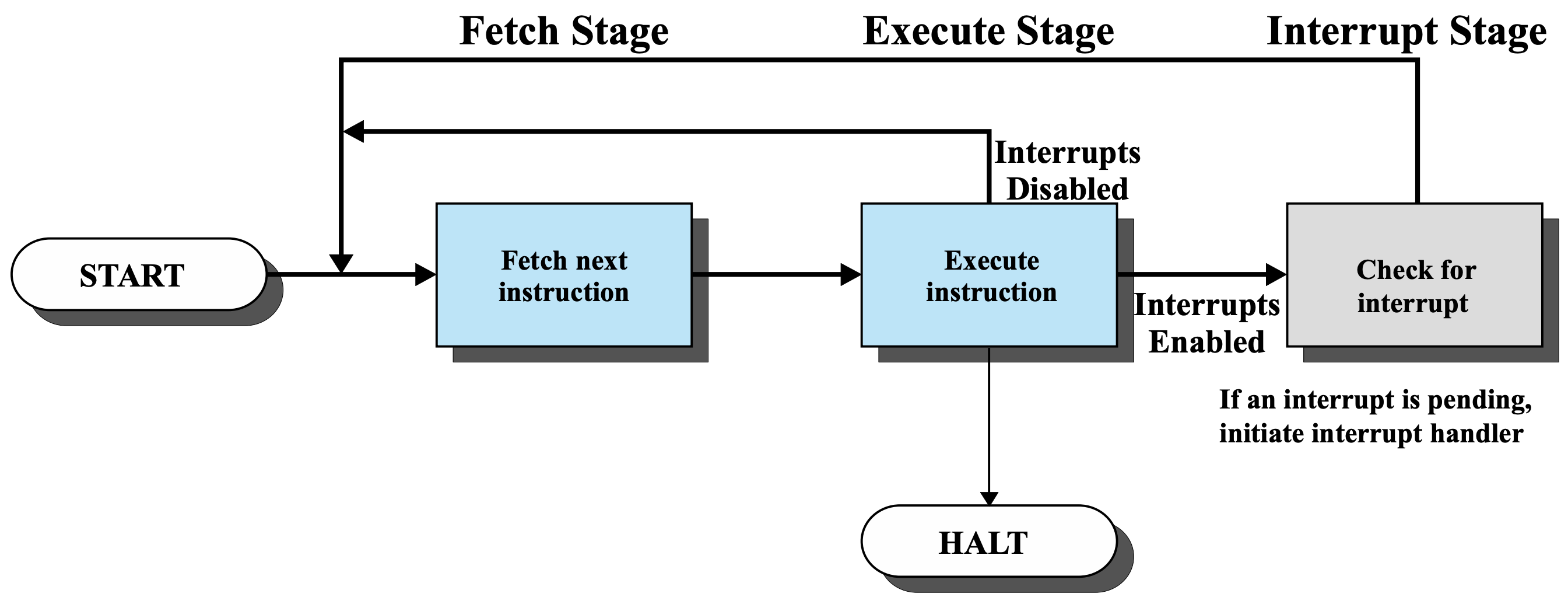
이전 글에 있던 그림에서 Interrupt가 추가 된 그림이다. Fetch - decode - Execution - Interrupt check 를 한다. Interrupt가 disalbed되어 있다면 하던대로 계속 명령어 실행을 반복한다. Enabled되어 있다면, PC의 시작주소를 interrupt handler의 시작주소를 넣어준다. interrupt handler는 함수라고 생각하면 되는데 kernal mode에서 실행되는 함수라고 한다. 보통 어셈블리어로 코딩되어 있다.
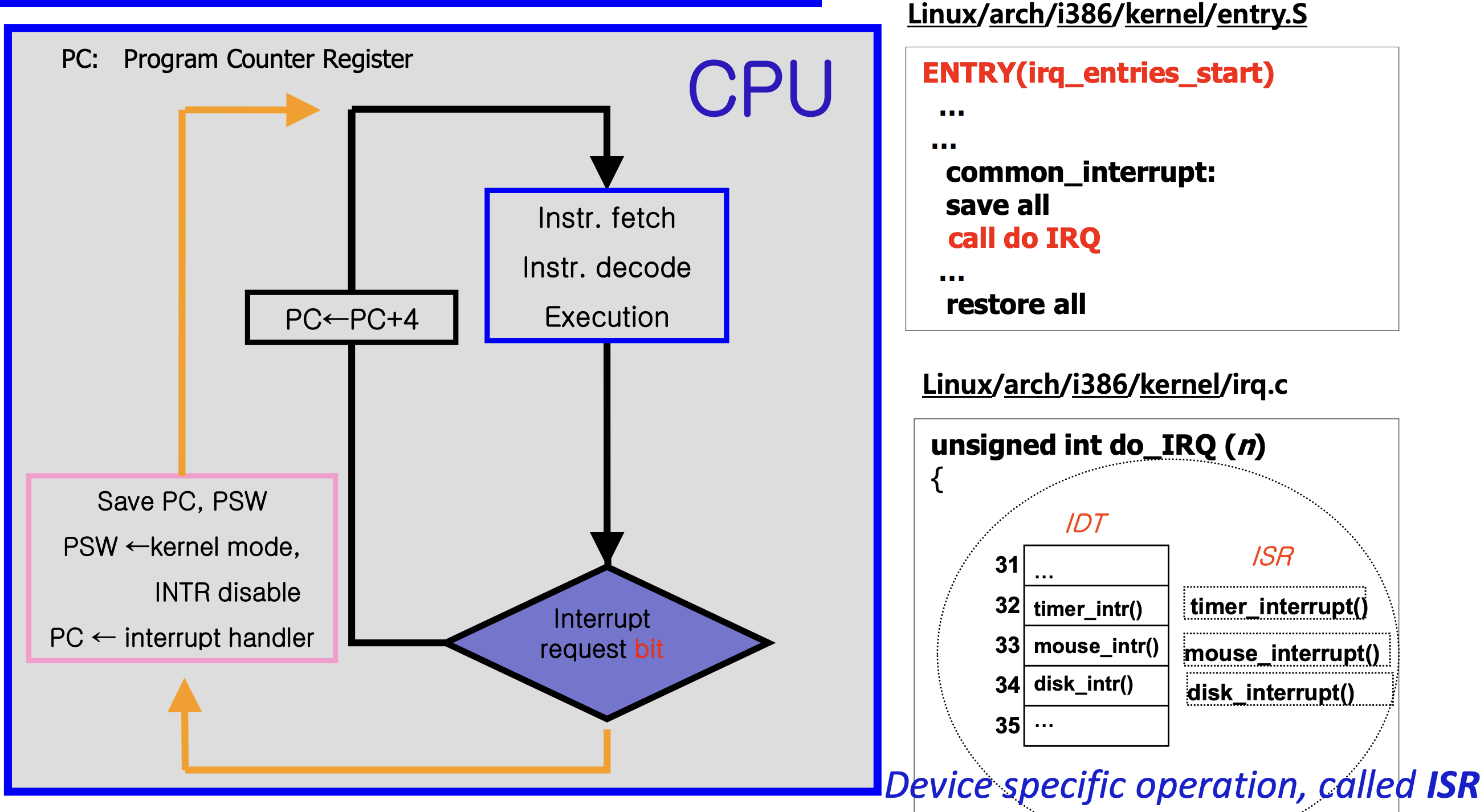
CPU는 명령어 실행이 끝나고 항상 Interrupt가 왔는지(enabled) 안왔는지(disabled) 체크를 한다. Interrupt과 왔을 경우에 어떤 일이 발생하는지 보다 자세하게 살펴보자. 바로 위의 그림을 보면서 글을 읽으면 된다.
아까전에 PC를 interrupt handler의 주소로 바꿔준다고 했었다. 근데 이걸 막 바꿔주면 CPU가 원래 하던 작업으로 돌아 올수가 없기 때문에 현재 하던 작업 상태를 저장을 해주어야 한다. 저장 공간은 stack 메모리 공간이라고 한다. 왼쪽에 핑크 상자에 보면 PC, PSW를 저장한다고 한다. 왜냐하면 PC는 interrupt handler의 주소로 바꿔야하고, interrupt handler는 커널 모드에서만 실행이 되기 때문에 PSW를 kernal mode로 바꿔저야 한다. 그래서 일단 PC, PSW를 저장해준다. 그 이후 PSW를 커널 모드로 바꿔주고 Interrupt를 disable로 만든다. 왜냐하면 Interrupt를 수행중인데 다른 Interrupt가 들어와서 충돌이 일어나면 안되기 때문이다. 마지막으로 PC에 interrupt handler의 주소를 넣어주면 자동적으로 CPU는 Fetch - decode -execution을 하며 Interrupt를 수행하게 된다.
그림의 오른쪽에 있는 코드들은 실제 Linux에 구현되어 있는 코드이다. 어셈블리어로 작성되어 있고 눈여겨 볼 부분은 save all 이다. 사실 PC, PSW만 저장하면 되는 것이 아니다. 레지스터는 거의 대부분 공용 레지스터 이기 때문에 이것들에 있는 내용들도 미리 저장을 해주어야 원래 하던 작업을 할 수가 있다. call do IRQ을 하게 되면 C언어로 작성된 코드가 실행되는데, 매개변수로 n을 넘겨주고 있다. 저 n이 바로 interrupt vector(IRQ #)이다. 어떤 interrupt가 어떤 번호를 가지고 있는지는 Interrupt Descripter table(IDT) 라고 하는 Mapping table에 저장되어 있다. 그리고 이제 특정 Interrupt에 맞는 서비스를 해줘야 하는데, 그것을 Interrupt Service Routine(ISR)이라고 한다. 주의할 점은 Interrupt handler는 저 모든 과정을 총괄하는 것이고 ISR은 interrupt handler에 속해있는 일부분이다. 같은 거 아님.
모든 작업이 끝나면 restore all을 하여 PC, PSW, 각종 레지스터에 원래 있던 정보가 다시 저장된다. 그리고 원래 실행되던 프로그램을 이어서 실행하게 된다.
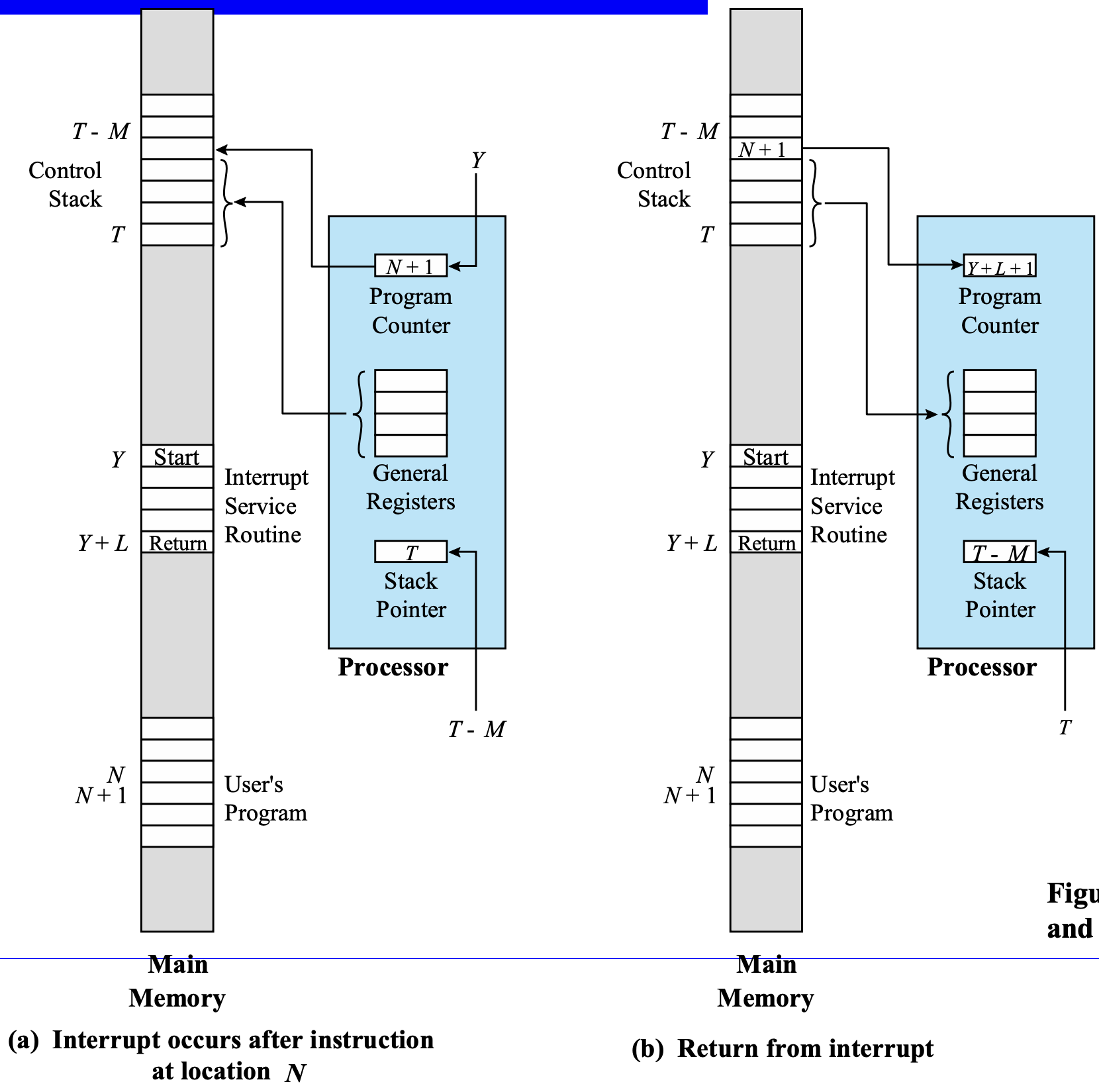
위의 그림은 interrupt 가 실행될 때 machine states를 나타내는 그림인데 사실 이해하기 좀 어렵게 그려져 있다. 전공책이 그렇지 뭐.
알파벳이 무엇을 나타내는지 정리하고 살펴보자.
T: Stack Pointer 레지스터가 가리키는 기본 위치.
M: 저장할 레지스터의 총 길이. PC, PSW까지 포함한 길이임.
Y: interrupt handler의 시작 주소를 나타냄. 그림에서는 ISR로 나와있어서 좀 헷갈림.
L: ISR의 명령어 갯수.?
(a)에서 N 이라는 위치에서 명령어가 실행이 종료되면 PC는 자동적으로 N+1로 업데이트가 되어있다. 그리고 interrupt가 발생한 상황이다. 일단 PC, PSW를 메모리에 저장하고, PSW <- kernal mode, Interrupt disabled, PC <- interrupt handler. 그리고 interrupt handler에 막 접근해서 원래 레지스터에 있던 정보도 다 저장한다. 이 때 저장하는 길이가 M-2인 것이다. PC, PSW 합쳐서 메모리에 총 M만큼 저장했다. 그래서 stack pointer 도 T-M으로 바뀌었다.
(b) Interrupt 실행이 종료되면 PC는 자동적으로 다음 주소를 가리키니 Y + L + 1로 바뀌어 있다. 이제 아까 하던 작업을 이어가야 하니 Restore 작업을 해주게 된다. 메모리에 저장되어 있던 레지스터 정보들을 다시 불러오고, PC: N+1로 바꿔주고, PSW 바꿔주고, stack pointer도 T로 바꿔줘서 임시저장된 것이 없어졌다고 해줘야 한다.
이것을 나타내는 그림인데, 중간 과정이 많이 생략된 그림이라서 사실 공부하기에는 좋은 그림은 아니다.
Interrupt 와 exception의 차이
CPU 내부에서 발생하는 interrupt를 exception이라고 이해하면 된다. 둘의 차이점 하나는 interrupt는 CPU 외부에서 발생한다는 것이고, exception은 CPU 내부적으로 발생한다. exception는 CPU 내부에서 발생하므로 CPU clock과 동기화 되어있다고 할 수 있다. 반면 interrupt는 CPU clock과는 무관하다. 그렇다고 둘은 다른게 아니다. 리눅스 기준으로 이름만 다를 뿐이지 처리과정은 완벽하게 동일하다. 아까 위에 있는 그림 중에 Linux 내부 코드가 같이 있던 그림이 있었는데, 그 그림에서 IDT 의 주소가 32부터 시작했다. 그럼 0 - 31 까지는 도대체 뭘까 궁금했는데 바로 exception과 관련된 것들이 0 - 31에 있다고 한다. 그럼 exception은 언제 발생할까?
user mode에서 fetch를 하려고 했는데, kernal mode에서 실행되는 명령어라면 exception이 발생한다. fetch한 명령어의 opcode가 잘못되었다면 exception이 발생한다. 0으로 나누는 경우가 있다면 exception이 발생한다. Interrut는 명령어 실행이 끝나고 체크를 하지만 exception은 fetch - decode - execution 이거를 하는 중간에 발생한다. exception이 발생하면 하던 명령어 실행을 중단하고 PC, PSW 저장하고.... 쭉 하다가 exception handler를 PC에 넣고 exception을 처리를 하게 된다.
-- illegal address, illegal opcode, divide by zero
정말 중요한 차이점 하나더 나왔다. interrupt는 현재 명령어 실행이 끝나고 처리가 되지만, exception은 명령어가 끝나기전에 처리될 수도 있다. 아래 표에 둘의 차이점을 정리해보았다.
| Interrupt | Exception |
| CPU 외부에서 발생 | CPU 내부에서 발생(현재 명령어 실행하는 동안) |
| CPU clock과 비동기(Asynchronous) | CPU clock과 동기화(synchronous) |
| 현재 명령어는 실행이 완료된다. | 현재 명령어 실행이 완료되지 않을 수 있다. |
| I/O device, system timer... | illegal address, illegal opcode, divide by zero |
'필기 > OS' 카테고리의 다른 글
| [OS] Time Sharing Systems. (1) | 2022.03.29 |
|---|---|
| [운영체제] OS의 역할, OS의 발전 (0) | 2022.03.27 |
| [운영체제] I/O 디바이스, APIC (0) | 2022.03.27 |
| [운영체제] Instruction Fetch, Decode and Execute. (0) | 2022.03.24 |
| [운영체제] 개념, Memory에 대해, Register 일부. (0) | 2022.03.24 |




댓글